
Geospatial Foundational Disappointments

TLDR;
After 10²¹ FLOPs and 500 B patches, IBM’s TerraMind beats a supervised U‑Net by just +2 mIoU on PANGAEA; losing on 5/9 tasks, most other GFMs do worse.
Current pre-training objectives are unlikely to scale further with compute and data.
I am disappointed.
Benchmarks
There's been a lot of hype concerning Geospatial Foundation Models (GFM) recently. Just recently, IBM announced a new model , which is supposedly state-of-the-art (SOTA) across the PANGAEA benchmark. Specifically, in their press release they claim:
"In an ESA evaluation, TerraMind was compared against 12 popular Earth observation foundation models on [PANGAEA, a community-standard benchmark](https://ai4eo.eu/portfolio/pangaea/), to measure the model’s performance on real-world tasks, like land cover classification, change detection, environmental monitoring and multi-sensor and multi-temporal analysis. The benchmark showed TerraMind outperformed other models on these tasks by 8% or more."
Reading through the paper, I was dismayed to find this table hidden away in the supplementary materials rather than featured in the full article:

On the PANGAEA benchmark TerraMind‑L edges a supervised U‑Net by only ~2 mIoU points on average despite a fairly big pre‑training compute budget (~9 000 A100 GPU‑hours) . The win is decisive on some multi‑sensor tasks (e.g. +21 pp on MADOS) but it actually loses ground on five out of the nine datasets, including a –19 pp collapse on AI4Farms. For day‑to‑day workflows that already run a tuned U‑Net the practical upside looks marginal. Remember these are fine-tuning results, in which we take the pre-trained foundation model as an initialization point and re-train on each benchmark task. If these are to become useful one day, it's clear we need better base models.
Scaling Laws and Bad Objectives
The empirical language model “scaling laws”, which launched a thousand data center leases, tell us that for language modeling validation loss in transformers falls as a smooth power‑law of model parameters N, training tokens D and compute C across > 7 orders of magnitude.

Furthermore, the Chinchilla result states that holding compute fixed, performance is maximized when the training set has ~ 20 tokens for every parameter in your transformer models. Models trained on fewer tokens per parameter are described as under-trained, while models trained on more tokens are described as over-trained.
These two pieces of information give us a useful framework through which to evaluate the current state of GFMs. PANGAEA provides estimates of model and training dataset sizes, so we can plot this information against the mean performance gain vs a U-Net baseline on the PANGAEA benchmark. Remember, from the Chinchilla perspective we’re interested in the trade off between model size and training dataset size, measured in training tokens per model parameter.
N.B these are rough estimates since it's not always obvious what constitutes a training/patch/token for some of these models. In any case, we expect these numbers to be off by potentially a factor of 2-4 based on this. We estimate the size of the TerraMind from the size of the checkpoints on huggingface, assuming the weights are stored as float32, which results in approximate model sizes of 380M (~1.52 GB) for TerraMind v1-B and ~ 1 billion (3.79 GB) for TerraMind v1-L.

This figure plots each model’s training tokens per parameter (log‑scale) against its mean PANGAEA mIoU gain over a supervised U‑Net.
One can notice that most GFMs appear to be undertrained: Before TerraMind, most models sat at ≲ 0.1 tokens per parameter, or two orders of magnitude below the “compute‑optimal” ridge of ≈ 20 tokens per param found in language models. It is. perhaps unsurprising then that these models would underperform a U-Net baseline.
We also see that the TerraMind set of models lie several orders of magnitude past the existing set of GFMs in terms of training tokens per parameter, in a ‘data rich’ regime at > 1000 tokens per parameter. This likely contributes to the fact that they are able to outperform the U-Net baseline on some tasks.
A caveat on the 20 tokens/parameter rule: The “20 tokens/param” ridge comes from text, where tokens are discrete and the loss is cross‑entropy on next‑word prediction. Remote‑sensing tokens are 16 ×16 or 8 × 8 pixel patches with continuous radiance values and multimodal bands. That higher intrinsic entropy could shift the optimal ratio upward—or make the whole ridge fuzzier. Until we have true loss‑vs‑compute sweeps for EO we're just treating the 20 tokens/param as a heuristic. A loss‑vs‑compute sweep on a constant backbone is still missing in EO.
But at what cost? We also estimate each model’s training compute with the standard transformer rule, to get a sense of absolute scale, or total compute required to train the models. Measured in floating-point operations (FLOPs):
where N is the number of learnable parameters and D is the number of patch‑tokens processed during pre‑training. The 6 comes from ≈ 2 FLOPs per weight in the forward pass plus ≈ 4 FLOPs in back‑prop and is the same back‑of‑the‑envelope math(s) used by OpenAI, DeepMind and others. In cases like TerraMind which provide metrics such as 'total tokens processed', we just plug this values as D into the formula. In cases which report number of patches, steps and batch sizes, we multiply these three numbers to estimate D.
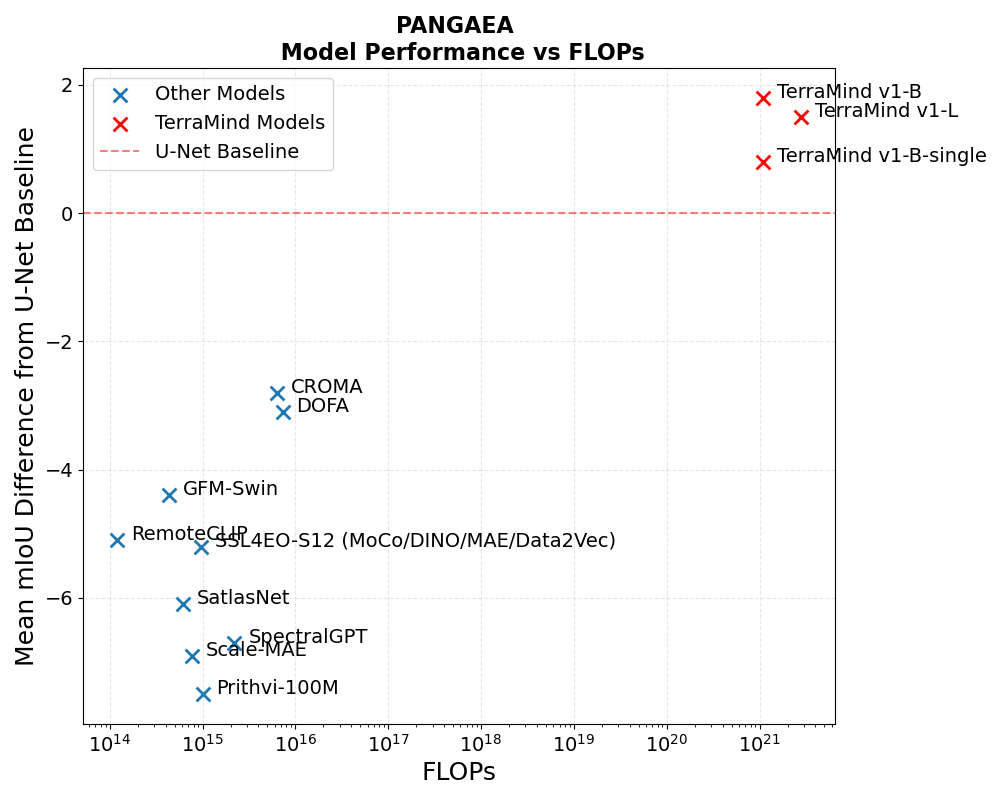
We’ve noted that by feeding ~500 B patch‑tokens (counting masked tokens, as MAE does) into a 380 M‑param encoder (≈ 1.3 k tokens/param) TerraMind ekes out a +2 mIoU mean gain vs the U-Net baseline. That win, however, costs ~10^21 FLOPs—about five orders of magnitude more compute than its predecessors. If a 100 000 × jump in compute buys roughly a 3-4 % relative mIoU bump. The curve is nowhere near the neat power‑law seen in NLP indicating bottlenecks that are deeper than just scaling.
Today’s GFMs aren’t failing because they’re “too small.” They’re failing because they’re under‑trained relative to capacity and misaligned with pixel-wise segmentation tasks. Before burning another million dollars in AWS credits and scaling models and datasets up further, we need sharper and more relevant pre‑training objectives and more information‑dense datasets; otherwise the next trillion tokens may move us only a few percentage points up the y-axis even for these limited tasks.
Flattening Performance
Most GFMs still train with pixel‑reconstruction or image‑patch contrastive losses: objectives that reward memorizing radiometric nuance but never tell the encoder what boundaries or classes matter. Add strong spatial and temporal redundancy (i.e daily shots of neighboring fields) and each extra gigabyte delivers few new bits. Personally I’d expect more new bits in examining time-series rather than spatial information. Compute goes up linearly, information rises sub‑linearly, so returns stall: TerraMind spends 10²¹ FLOPs for +2 mIoU. Progress will come less from bigger encoders than from task‑aligned pre‑training objectives (masked segmentation, cross‑sensor prediction) and dropping near‑duplicate patches before they hit the GPU.
Adoption and Marginal Utility
Ultimately we are asking the wrong question when it comes to GFM development. Ask most experienced practitioners in the field, and they'd be happy with solving a single problem well, let alone the myriad these models claim to solve. The challenge in building a geospatial solution rarely lies in training a model and grinding out +2% on your test set, but in other factors such as:
deploying the model at scale and inspecting the results,
communicating the results to disappointed clients and stakeholders
inevitably re-deploying your model when some weird edge case that wasn't contained in the data needs to be resampled.
Practitioners are unlikely to adopt new models unless the marginal utility resulting from these models is very large. Remember these are not just plug-and-play models as of yet: we have to redesign data pipelines, image tiling and result stitching in order to integrate them into existing workflows. Some of these models may be on the larger side too, so will require specialized hardware (i.e larger GPUs) when fine-tuning. Of course these models are released for free, although some companies expect to make money from them by making it easier for you to spend money on ‘GeoAI’ without a clear ROI. The cost of implementation remains, even if the cost of the model is zero.
Model developers face an uphill battle on multiple fronts when it comes to model adoption: they need to improve pre-training objectives and performance, design better and less redundant datasets and also minimize user friction when it comes to integrating their models.
I hope that we’ll see efforts in designing more appropriate objective functions for pre-training, careful study of whether existing efforts are scaling, and some actual use-cases before we burn the next batch of AWS credits.
Hi Christopher,
thanks for the feedback :) even if it's a bit harsh haha probably due to your disappointment. Let's put things in perspective:
Performance
- 4% better than UNets on average ((57.58 - 55.29) / 55.29) and also better in the avg rank.
- 7.5% better than the second-best foundation model in the benchmark ((59.57 - 55.29) / 55.29)
- It's worth noting that the FM encoders are generally frozen, while the UNet encoder is trainable. That setting was chosen to investigate the generalizability of the FM encoders in PANGAEA.
Model size and pretraining
- We use base and large as backbone sizes just as in ViTs. If you use a single modality you end up with 86M parameters for the ViT-B backbone, so with the patch embedding less than 100M. Same story for large. So not heavier than other models. Also UNets are not a lot smaller.
- Understanding how scaling data and compute in pretraining can help to get better models out is exciting isn't it? You are right to refer to the language domain where this works particularly well and I do see some scaling behaviour when comparing other models with TerraMind in your figures. However, I agree, we should not generally expect the same scaling behaviours people see in language.
Capabilities on top:
- UNets cannot generate synthetic data if they are constructed for a downstream task
- UNets cannot do Thinking-in-Modalities which can give an additional improvement
Overall:
You get a cool new model for free that is not bigger than other models, but better than many in a lot of settings and has some cool new capabilities.
Are you still disappointed? Then we should talk in more detail. :) I would really like to understand your perspective.
Johannes
Thanks Chris! Enjoyed seeing you on Matt Forrest ep on GFMs. I'm just getting into this space, but do you think you'd be interested in doing a 1+-year retro on this?