
Google is a Dream Killer
Don't Compete with Big Embeddings

A quick note on earth engine prices:
Google Earth Engine lowered their prices! Simon Ilyushchenko very generously mentioned a previous post I had made referencing the confusing economics of earth engine. While I think removing pricing for individual seats and lowering online pricing is a great step in the right direction, it unfortunately is unlikely to have a huge effect on the calculations in my post which were all based on the batch API. What I think is more likely to happen is that companies will have to choose between switching their batch pipelines (exporting) over to online workflows (high volume API, streaming etc…). Perhaps the lowering of the online API price means we’re likely to see xee gain more adoption in commercial settings.
TLDR;
Sounds like The Moose was a good cat ❤️.

Google shows that FMs don’t appear to scale effectively for linear-probing on tasks: I would not train another general EO FM right now.
It does not make sense to try to build a business on unproven and expensive technology economically. It does make sense to try to sell cloud services.
Even if embeddings were a proven geospatial company, it is impossible to compete with a killer unicorn when you are a show pony. Competing with Google’s distribution and subsidies is a brutal game

Thoughts on AlphaEarth Foundations
Google recently released global embeddings from their alphaearth foundation model (AEF). There’s been a lot of buzz around the embeddings themselves, here are some thoughts on what this means for Big Embeddings as an industry.
1. Read my lips: no new foundation models.
At least not in the general case. Google scaled their experiment beyond what any other company in the space could reasonably do. Have a look at the training data:
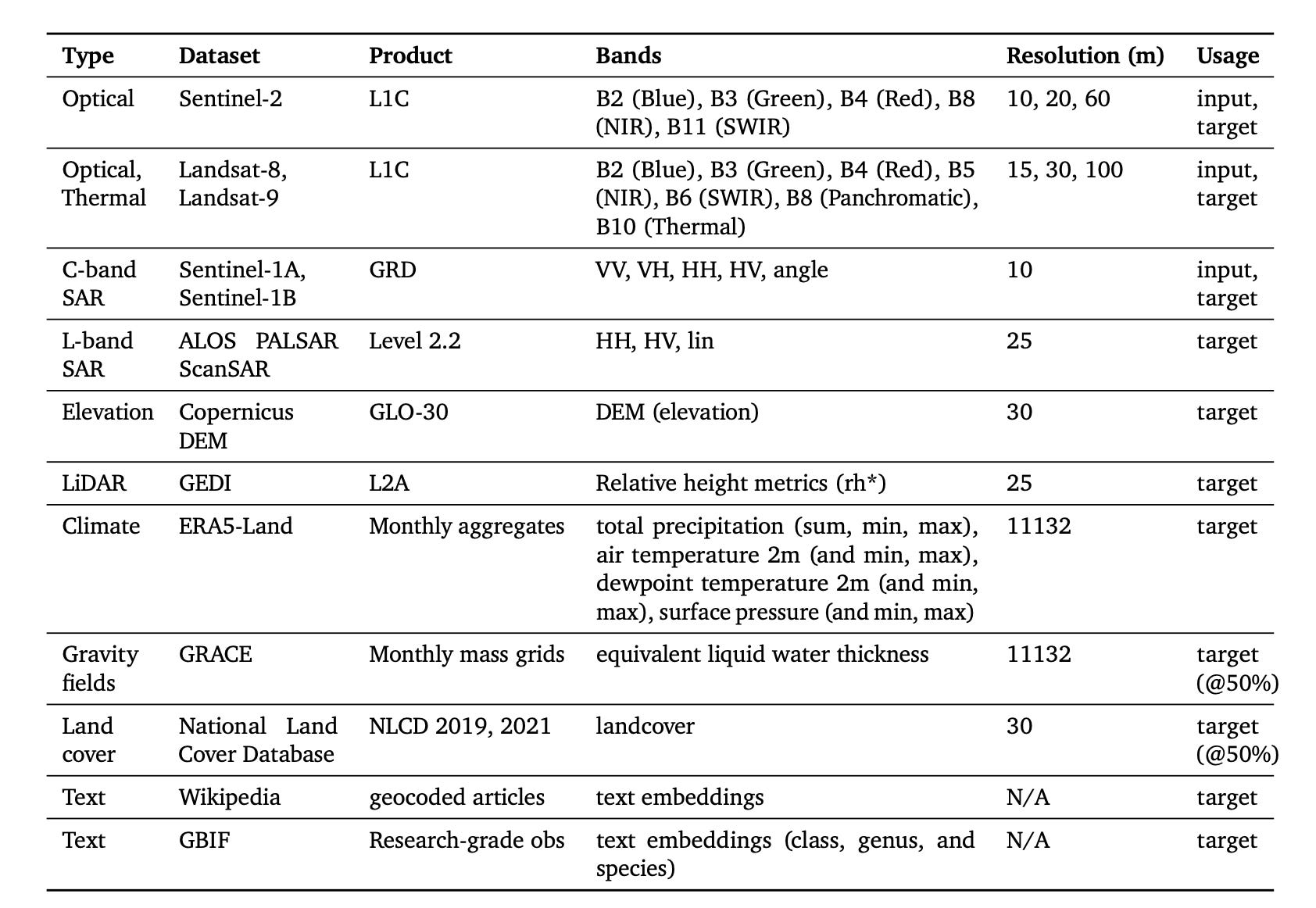
Although some sensors are conspicuously missing (notably MODIS and VIIRS), we can see they threw the kitchen sink at this model. Some interesting choices include: text from the Global Biodiversity Information Facility (GBIF) + Wikipedia, NLCD (only available in the US) and monthly aggregates of ERA5-Land. These are not all used as inputs. Let’s look at how the results scaled with increasing data:
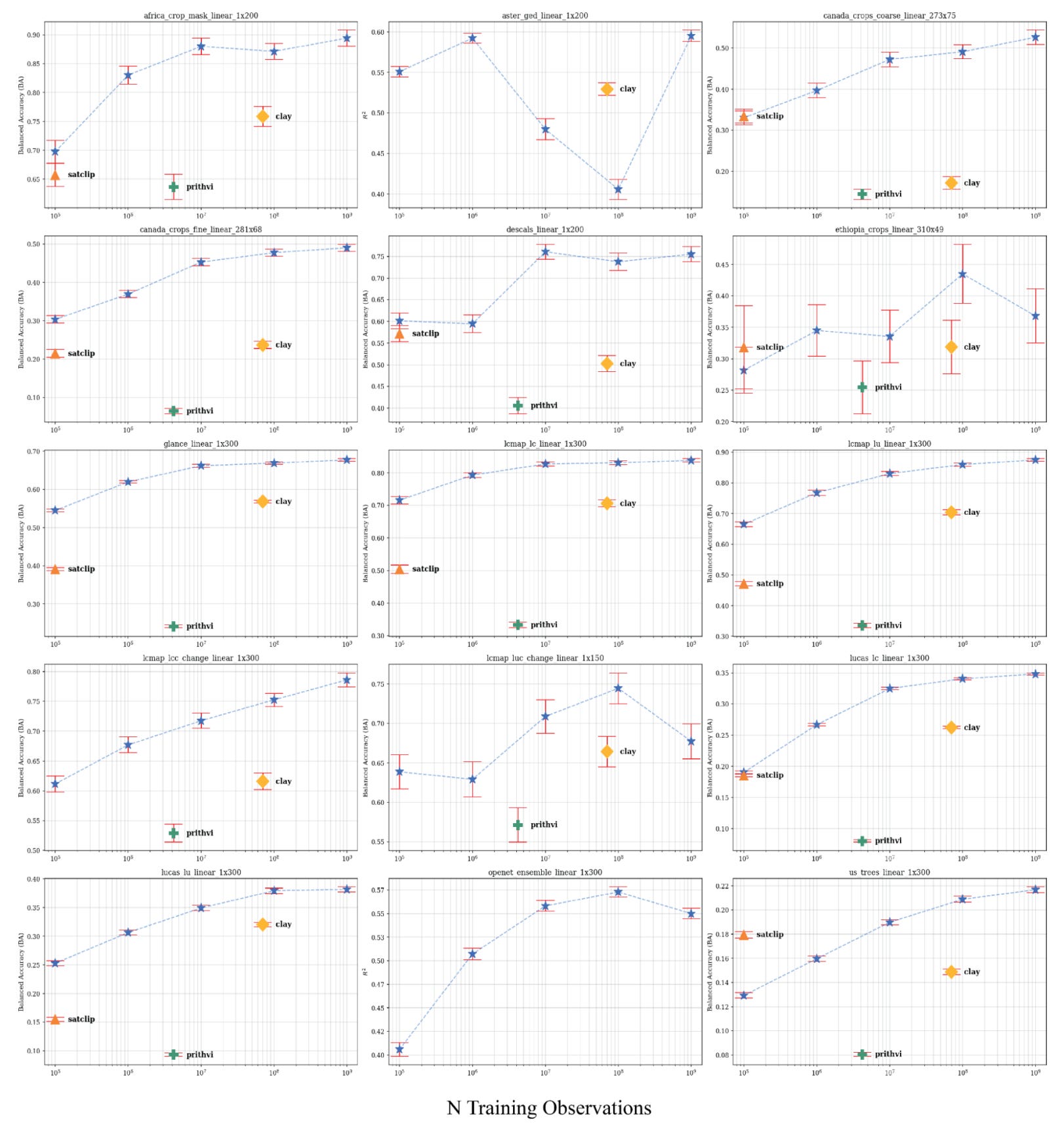
Across many of the 15 tasks, linear-probe performance saturates around 10^7-10^8 observations, with additional data yielding changes within the confidence intervals. A few tasks still improve, but the slope is quite small beyond this point on most tasks. On some tasks, the performance actually decreases with increasing data. This suggests weak returns for general-purpose embeddings in linear-probe evaluation, making large-scale training a highly questionable investment unless targeting a specific task that demonstrably benefits from scale. I will note that AEF appears to scale better than some other existing foundation models, but higher performing ones such as TerraMind are missing from these comparisons.
While AEF appears to outperform all other methods on the chosen benchmarks, it is also worth noting that both CCDC and MOSAIKS, two unsupervised methods appear to perform solidly on all benchmark tasks at much lower complexity than foundation models. In general, I’m growing a little weary of squinting at benchmark plots and tables: if AEF achieves balanced accuracy of 0.22 on us_trees and Satclip got 0.18 I’m unlikely to use either for a task that ressembles us_trees. Benchmarks are just the price of entry: we need them to know that a model is worth even looking at, but the true test is the real world!
2. Embeddings don’t look like a business:
I see people claiming that the future of EO is based on ‘geo-embeddings’, and that Google must think so too, because they released these embedding. I think this is wrong: zoom out! The product here is not the embeddings but where they were released: Google Earth Engine and associated cloud products. If anything, the fact that these were released globally without an explicit pay-wall should tell you what value Google assigns to these. While this is indeed a big moment as it represents the first global set of embeddings which are so widely and easily accessible, I think this will play out more like the release of Dynamic World or Impact Observatory’s LULC map rather than ChatGPT (sorry Krishna I stole your point but imitation is the sincerest form of flattery). These are impactful data products that need to be used with others in order to be useful. Meanwhile, if you do want to access these, and use them in conjunction with other raster datasets, you know where to do that. And don’t forget to sign up for a cloud project, and can we also interest you in some cloud storage and compute while you’re here 😉?
Being an embedding application layer is simply a losing proposition for every company: you pay for cloud resources to host and store your embeddings, millions to train your own models (please don’t), engineers to build your APIs, and THEN you have to convince customers to hand over their cash for your embeddings. This equation changes when you provide the compute, storage, and your embeddings just happen to be a cherry on top that users can choose to use, provided they pay for cloud resources that you provide.
Playing devil’s advocate for a second: the flip side here is that you potentially be able to pick up customers that can’t and won’t use GEE. There is also a case to be made for problem-specific embeddings with verified gains in task cost, but we have yet to see anyone in the space show hard data on embeddings being a cheaper way to develop valuable applications.
3. The race to the bottom:
Google is offering $5k grants to support people building on this product. Have you ever heard of a company paying people to use their killer product? What are the implications of this? Even if we take the counterfactual position that these embeddings are indeed a killer product and Google is attempting to flood the market a-la Uber with their cheap rides, what does this mean for start-ups looking to compete against something that’s currently been assigned financial cost of almost $0?
From my initial experiments on retrieval on smallholder crops: these embeddings are appear to be potentially useful (more on this coming soon), although I have some reservations about how they were trained. It’s still clear we have not figured out how to effectively interact with geospatial embeddings, and what the true cost and time savings are from using them. Verification is still the biggest problem, and we encounter it over and over again in EO: you can build a great looking model, but how do you go about verifying it’s detecting the actual signal you care about? I would love to see more companies working to solve this problem, although the answer may be buy timely high-resolution imagery.
4. One more time with feeling:
What does this mean from an industry perspective? A complex solution looking for a problem is a major red flag: sometimes ideas consume so much capital and energy that they become too big to fail. Whole companies stake their future on them, people bet their careers, and investors bet their dollars. However, there are few companies in the space that can afford to sustain these types of ideas until they become useful, so if you are considering it please consider the economics of the endeavour as much as you consider the technology. Having organizations spin-up and fail unnecessarily erodes trust in the industry as a whole and is likely to harm it in the long term.
4. Shameless self-plug:
I’m starting a podcast with my good friend Krishna Karra. The first episode will probably be about embeddings, unless we all lose interest before we record.