
Applied Geospatial: Greatest Hits 2025
A Slightly Unhinged Year in Review

TLDR in 2025;
I am super, super grateful to all of you for subscribing and reaching out. I got to meet/chat with so many cool people in earth observation this year, and I hope this continues next year.
Forecasted US almond yield.
ERA5: don’t believe his lies.
No one really wants to read about anomaly detection, even if it’s on fancy newly-released hyperspectral data.
Foundation models: can’t live with ‘em, can kind of live without ‘em unless you’re trying to be an influencer in the niche field of earth observation.
Benchmarks kind of suck, but we also need them because we don’t have anything else.
Google released embeddings, they’re honestly pretty good, and I’m still planning on milking them for content in 2026 (but I think they shouldn’t have included all that auxiliary non-EO data in training).
We released Geovibes and I used it to map catfish farms, so it’s totally not a useless demo.
Read on to see my slightly unhinged thoughts about my posts.
Technically from 2024, but my first post on substack and my friends with kids say your favorite one is usually the first-born. They don’t say this out loud, but I can see it in their eyes and soul.
This one was particularly fun to write and iterate over. Initial results were extremely disappointing, but I read up on the almond growing season and realized I was modeling everything wrong: bloom occurs earlier in the year than greening, so it turned out NDVI from the prior year was extremely strongly correlated with yield in the next year.

Another fun one! I was quite pleased with this analysis as it resulted in some folks from a start up working specifically on measuring/forecasting precipitation reaching out for a chat. This is when I started realizing that I could use substack posts as a sort of social query to find interesting people to chat to.
I was astonished to see how different various sources of precipitation data were over CONUS. In previous lives at yield-modeling companies I think some of us might have taken for granted how similar different datasets can be. Funnily enough, I actually have an unpublished draft on a similar analysis of divergences in growing degree days over the US corn belt where the differences are perhaps even more striking. Maybe one day I’ll get back around to publishing it!This was quite early on in my writing (I mean it still is), and emojis were still kind of funny as an LLM-ism. I really dislike them now. You’ll also notice traces of LLM-isms in the titles, (‘why this matters’ etc…) which I also really dislike. We live and we learn.
This one was an interesting one: it received the most attention on social media out of any of my posts at that point, due to Wyvern’s open data release, but was the least read (only 90 reads). My original plan was to actually perform anomalous change detection (ACD) between pairs of images, which I find much more interesting and relevant to earth observation, but ran out of time, so settled for anomaly detection. I still plan to write about ACD one day, it is an underrated technique for change detection in remote sensing.
It was at this point it started dawning on me that I was wasting my time chasing social media clout writing about things I thought people were interested in, instead of just writing things I myself was interested in. I also thought people might be interested to see the code used to generate the images (they were not).
This one also has emojis. I’m sorry. Also the LateX didn’t render.
People are really interested in foundation models in EO, as well as contrarian takes. Look at this plot of my subscribers, can you tell when I started being a contrarian asshole?
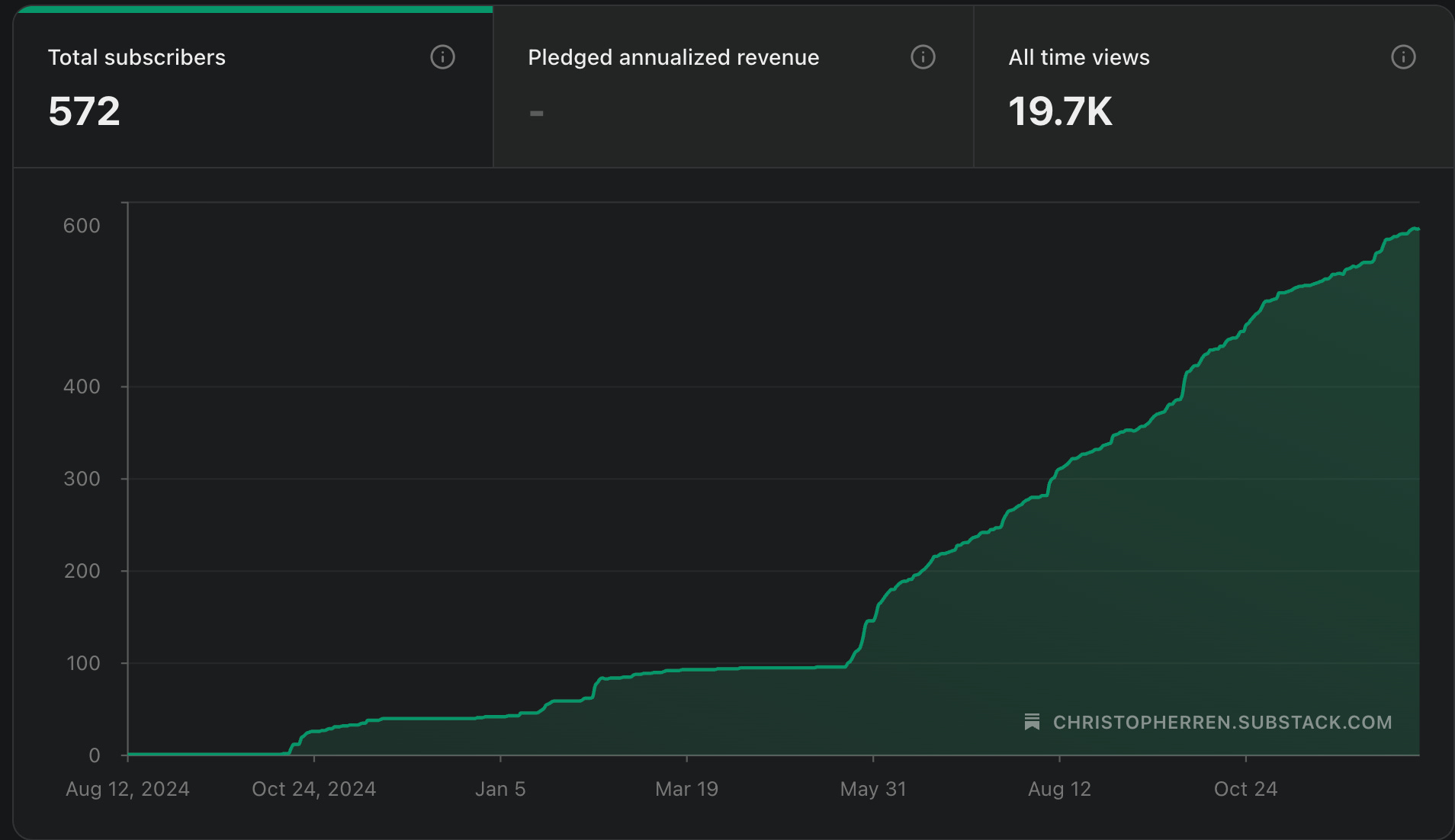
I still think EO foundation models are a big money and time sink. If you don’t believe me, you should read Akis’ Spectral Reflectance post which is much more thoughtful than this post.
Fundamentally I’m very grateful though because when this post ‘took off’, I got to meet many people I would now call my friends, who ended up helping me with geovibes. We even have a secret slack channel where we complain about foundation models. Also, shoutout to Johannes Jakubik the lead author of TerraMind who chose to engage with me on the post (see the comments), and actually took the time to reach out and chat too!
Something I am still thinking about that is related to this post: what is the best you can do with a pixel-wise model + post processing on all of these benchmarks?
More of a commentary on how benchmarks don’t really reflect reality, and that there are some particularly tricky inference issues specific to geospatial that even major labs/releases are not immune to based on some of the artifacts I’ve seen in outputs this year. I had a lot of fun thinking about different types of geospatial errors, and got to make the Santa Fe Quartet.
Happy to report 0 emojis in this one.
The thought that sparked this one is still bothering me to this day: how much does it cost to make a map? I had heard from friends that worked at companies that had done global deployments that things sat in the $5k - $15k range. So I decided to try and extrapolate how much it might cost to develop a global map on GEE.
I still think about this a lot: no one knows how much anything costs! I had big plans to write continue writing about this subject, but unfortunately failed to make inroads with any organizations doing these things. I don’t blame them, money is a sensitive subject. If you are a company that would like to talk about this however, please do reach out!
A cool thing that came from this post is that Simon Ilyushchenko mentioned this post in an announcement stating that Google had changed the pricing structure of GEE!
I still think these embeddings are a little ‘overfit’ because of this, but damn they are pretty good! An experiment I’ve been meaning to run: sample built area over cities at different elevations in the world, can you train a model to recover elevation from the AEF embeddings? If you can, then they are a little overfit, if not then I stand corrected!
Would call this one a puff piece: when I started the blog I made a promise to myself that I would have to write a least a single line of code for each blog post. This one was pure commentary, but at least it wasn’t AI slop.
I have been thinking about this for a long time, so it felt really good to release geovibes and write about it!
The gist is: you can search embeddings with just a notebook and a downloaded duckdb table + faiss index. That’s really all you need. Making the embeddings is a different story! We should think about making these (unproven) tools as accessible as possible so people can test them out in the real world.
Dog-fooding geovibes and mapping aquaculture/catfish farms in Alabama. It turns out the CDL’s map is quite poor (confuses open water and aquaculture), but with geovibes it’s fairly easy to map these very distinctive levee ponds! Was happy to close out the year with this, and put geovibes to use.